예시로 알아보는 Python Heap Memory
프로세스 메모리는 크게 code, data, stack, heap 영역이 있는데 이번 글에서는 stack, heap 영역을 다룰 예정이다
그럼 heap 영역은 왜 알아야 할까?
- 파이썬은 모든 게 객체이기 때문, 즉 값을 heap에 저장하고 stack에서 참조한다
- 모든 thread는 자기 process heap memory 영역을 공유한다 이걸 이용해서 좀 더 유연한 프로세스를 만들 수 있다
- 객체를 무분별하게 생성하지 않기 위해서
- 버그를 찾기 위해
- 기타 등등…
간단하게 예시를 들면
1 | from threading import Thread |
실행 결과는
True
True
True
False
heap 메모리 그림을 보면 프로세스 실행 3초 뒤
thread2가 detect_word를 cat으로 바꾸었기 때문에
heap 메모리를 공유하는 thread1의 detect_word도 cat을 가리키고 있다
dog는 reference counting이 0이 되어 GC에 의해 메모리 해제된다
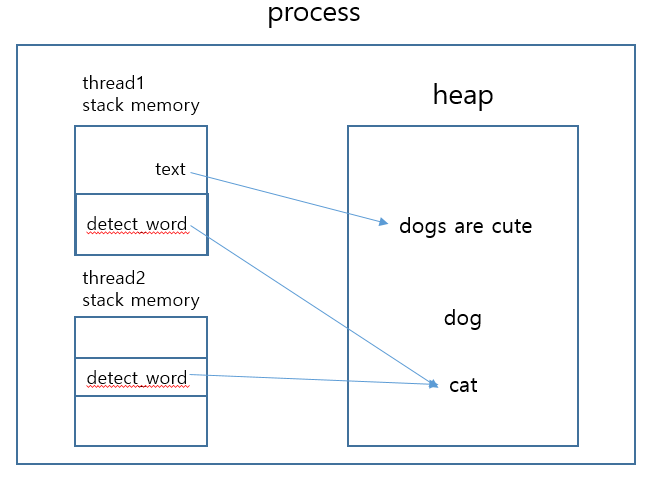
간단한 예시지만 이런 특징을 사용해서 좀 더 유연한 프로그램을 만들 수 있다
thread 프로그래밍이 장점이 많지만 메모리를 공유하기 때문에 연산 작업할 때는 lock을 사용하여 thread-safe하게 신경 써야 한다
하지만 lock은 처리 시간을 느리게 하므로 주의가 필요하다
자료구조 시간 복잡도
자료구조별 시간 복잡도
실무에서 주로 사용했던 자료구조 시간복잡도를 정리해봤다 작업의 시간복잡도를 보고 효율적인 자료구조를 선택하자
| 자료구조 | 접근 | 검색 | 입력 | 삭제 |
|---|---|---|---|---|
| array list | O(1) | O(n) | O(n) | O(n) |
| set | O(1) | O(1) | O(1) | O(1) |
| stack | O(n) | O(n) | O(1) | O(1) |
| queue | O(n) | O(n) | O(1) | O(1) |
| singled-linked list | O(n) | O(n) | O(1) | O(1) |
| doubly-linked list | O(n) | O(n) | O(1) | O(1) |
| hash table | N/A | O(log(n)) | O(log(n) | O(log(n) |
| binary tree | O(log(n)) | O(log(n)) | O(log(n)) | O(log(n)) |
습관적으로 탐색할 때도 list를 많이 사용했는데 탐색할 때는 list 대신 set을 사용하자
시간 복잡도 그래프
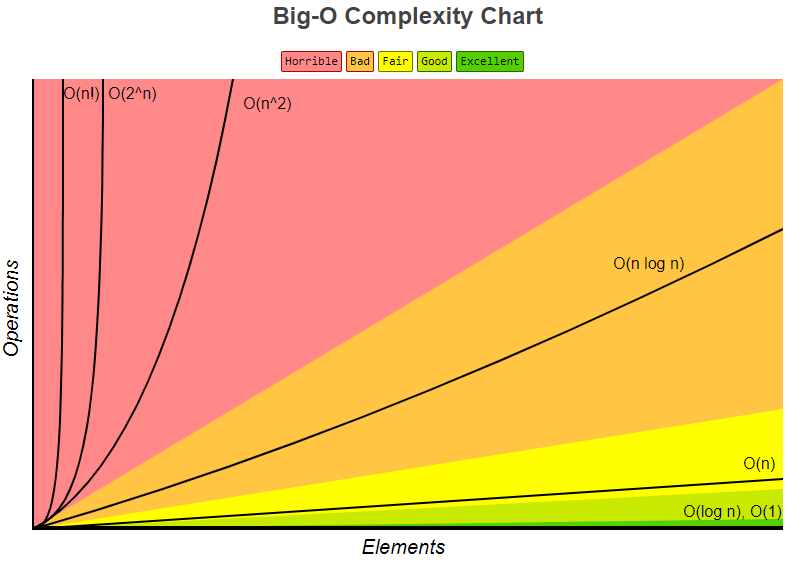
참조링크
Python 병렬처리로 크롤링 시간 단축하기
thread 와 concurrent.futures 사용으로 병렬 처리하기
1. thread 사용으로 병렬 처리
저번 코드에서 save_img 함수를 multi thread로 실행하면 좀 더 빠른 결과물을 얻을 수 있을 것 같다
1 | import requests |
작업결과
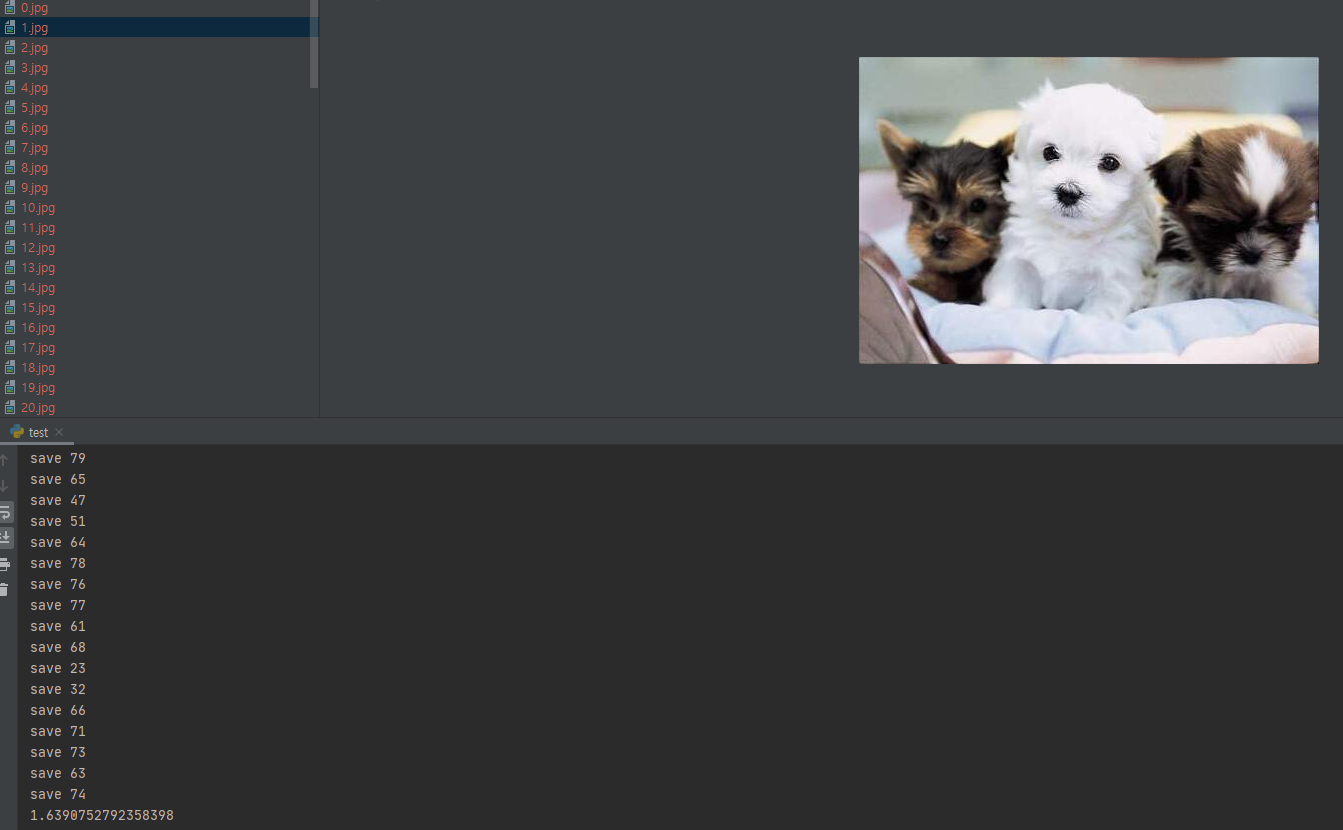
작업 시간이 1초대로 단축된 걸 확인 할 수 있다
2. concurrent.futures 사용으로 병렬 처리하기
concurrent.futures는 비동기 처리 고수준 인터페이스 모듈이다 이 모듈을 써서 작업 시간을 줄여보자
1 | import requests |
작업결과
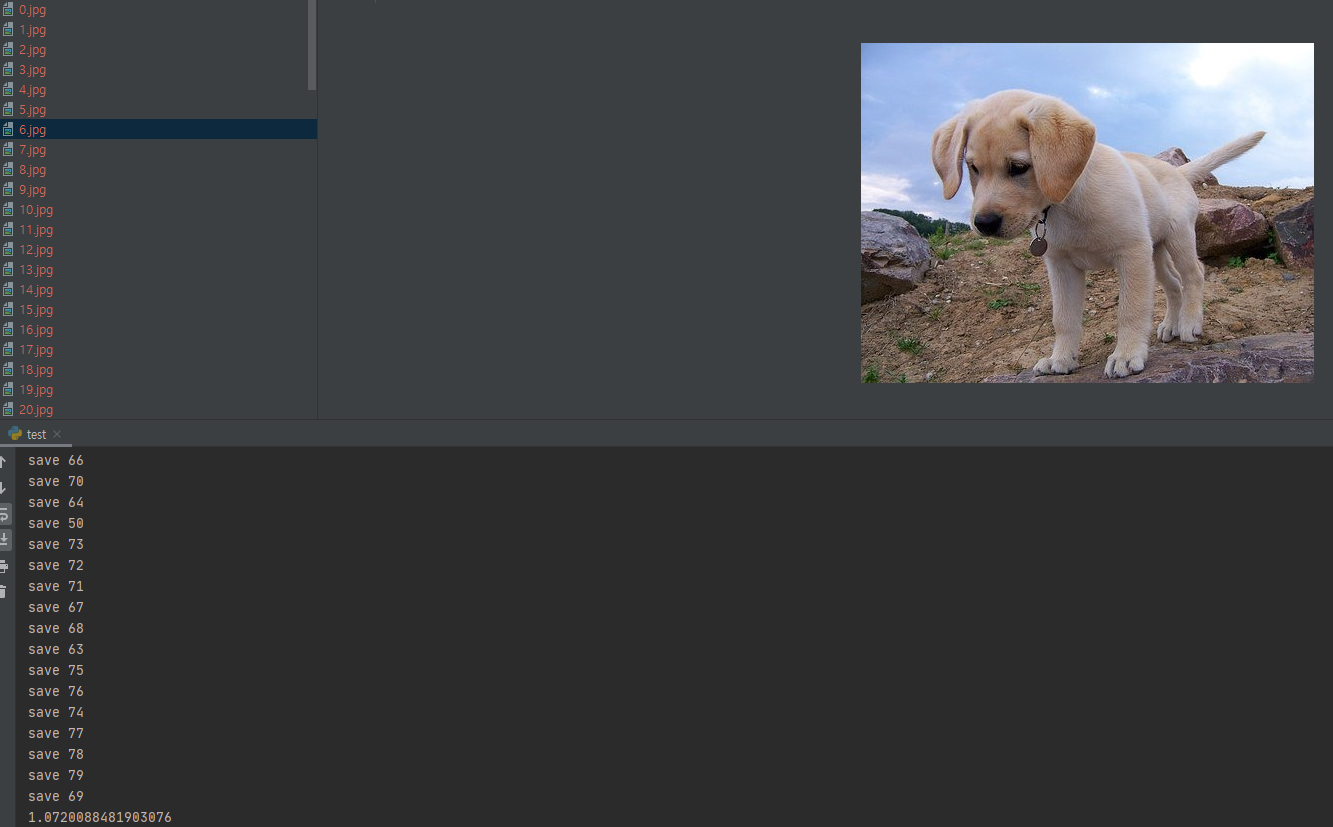
마찬가지로 작업 시간이 1초대로 단축된 걸 확인 할 수 있다
결론
- I/O 작업이 있을 때 병렬 처리 작업을 활용하여 작업 시간을 단축시킬수 있다
- 상황에 따라 다르지만 될 수 있으면 thread 모듈보단 고수준 비동기 concurrent.futures 모듈을 사용하자 병렬처리 작업의 결과물을 리턴 받는 등 다양한 함수를 제공한다 참조링크