Beautifulsoup으로 이미지 크롤링 안될 때 다른 방법으로 크롤링하기
이미지 태그나 클래스명 등으로 크롤링 하려는데 안될 때 어떻게 해야할까?
여러가지 방법이 있겠지만 이번 글에서는 python, re(정규식) 모듈, requests 모듈을 이용해서 크롤링을 해보려고한다
다음 이미지에서 강아지를 검색하면 브라우저 검색창에 아래 url이 나온다
1 | https://search.daum.net/search?w=img&nil_search=btn&DA=NTB&enc=utf8&q=%EA%B0%95%EC%95%84%EC%A7%80 |
이 url을 이용해서 python으로 request를 날려보자
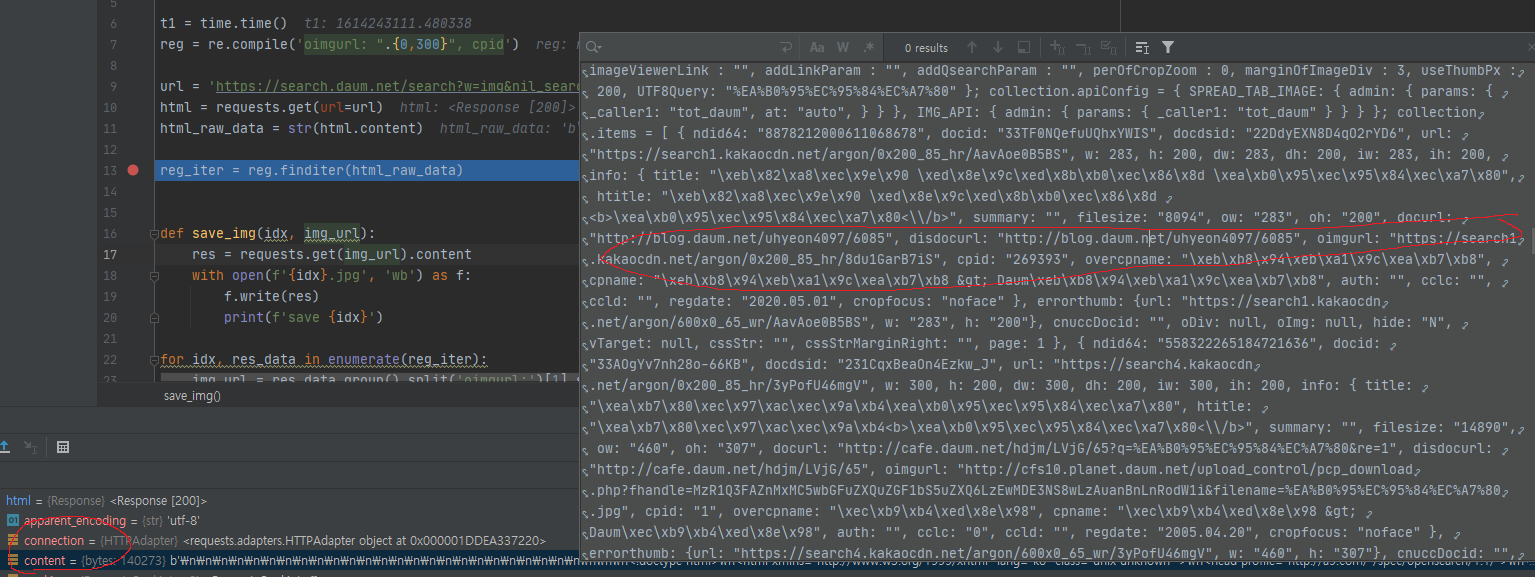
아래 사진을 보면 이미지 불러오는 url이 보인다 저 url을 정규식으로 추줄해보자
더 좋은 정규식이 있을 텐데 저는 저렇게 해서 추출했습니다
(정규식 내용은 분량이 큽니다 관심이 있으면 따로 찾아보자)
- 코드를 보자 정규식을 선언하고
- url을 뽑아내는 전처리 작업을하고
- 이미지를 저장하는 코드룰 볼 수 있다
1 | import requests |
이렇게 하면 이미지가 저장되는 걸 볼 수 있다
작업이 4초 넘게 걸렸는데 다음 포스트에서는 thread 와 비동기 함수를 사용하여
작업 시간을 단축시키는 포스트를 올려보겠습니다